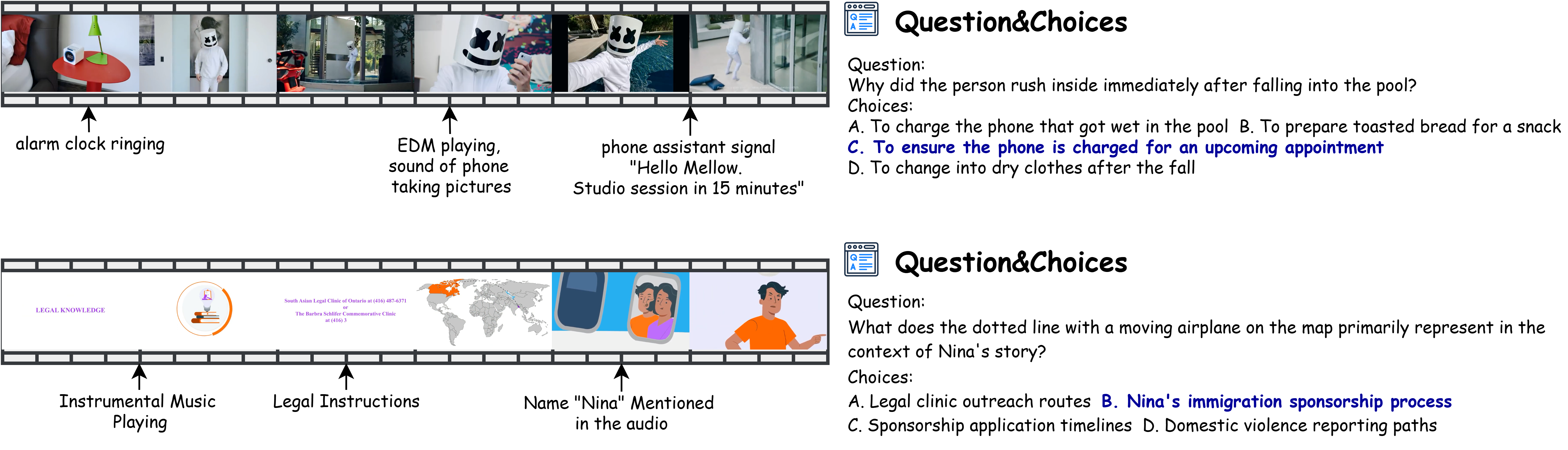
Examples from our Daily-Omni benchmark, showcasing diverse audio-visual reasoning questions.
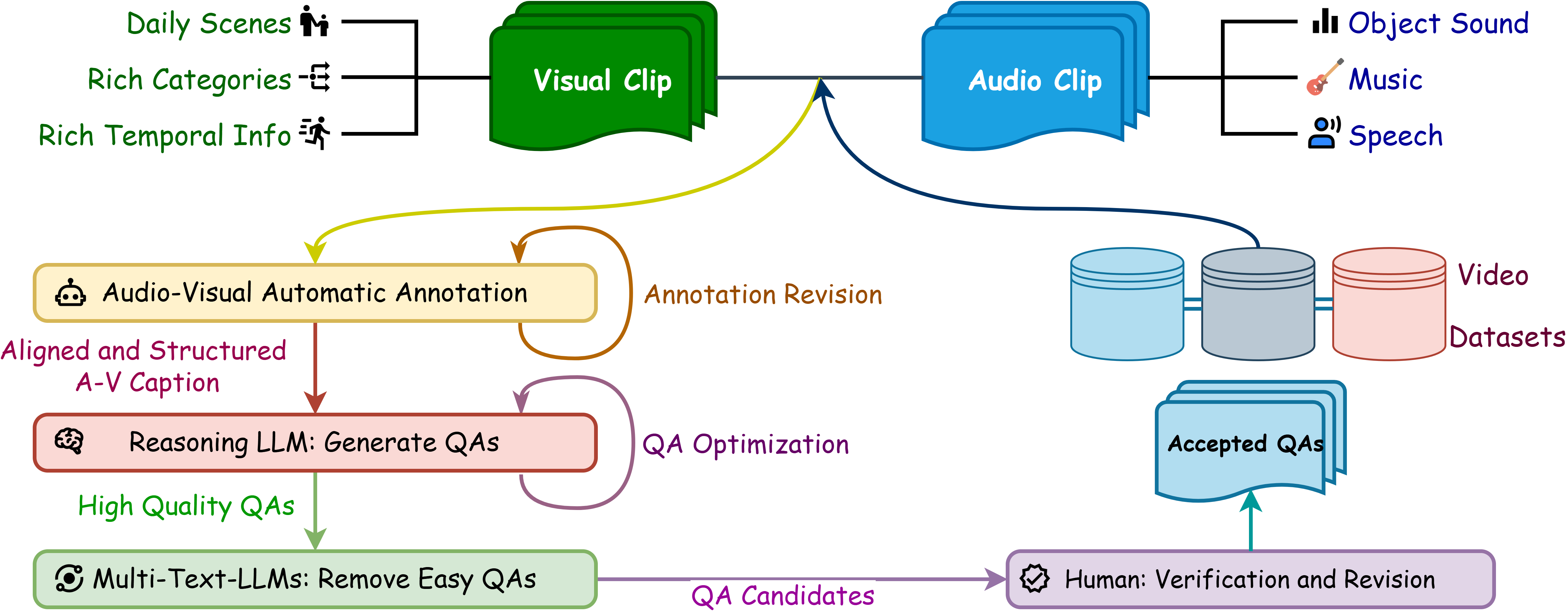
The Question-Answer generation pipeline of Daily-Omni.
.png)
Annotation Detail showing how we align audio and visual events.
.png)
Architecture of Daily-Omni Agent.
.png)
We showcase three diverse scenarios: (1) AV Temporal Alignment in a product review, (2) Cross-modal Reasoning in a vlog, and (3) Logical Inference in an educational video. Correct answers are highlighted in blue. The models’ predictions are marked with a green checkmark for correct answers and a red cross for incorrect ones, highlighting the persistent challenges in fine-grained multimodal understanding.
Performance comparison of MLLMs on Daily-Omni. Random guess accuracy is 25%.
Abbreviations: AV Align = audio-visual alignment, Comp. = comparative, Ctx. Und. = context understanding, Evt. Seq. = event sequence, Infer. = inference, Reas. = reasoning.
Closed-source models are marked with (Closed); open-source models are marked with (Open).
| Methods | AV Align | Comparison | Context Understanding | Event Sequence | Inference | Reasoning | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| AGIBOT X-Lab WITA-Omni Preview (Closed) | 86.13 | 89.31 | 81.87 | 84.64 | 85.06 | 85.71 | 83.62 | 87.09 | 85.21 |
| Qwen3.5-Omni-Plus (Closed)† | 84.42 | 88.55 | 82.72 | 83.67 | 84.67 | 86.05 | 83.44 | 86.20 | 84.68 |
| Gemini 3.1 Pro Preview (Closed) | 83.61 | 86.26 | 79.79 | 82.35 | 81.17 | 84.57 | 81.76 | 84.00 | 82.79 |
| Doubao Seed 2.0 Lite (Closed) | 81.51 | 83.97 | 79.79 | 83.33 | 80.52 | 83.43 | 80.37 | 84.18 | 82.12 |
| NVIDIA Nemotron 3 Nano Omni 30B A3B (Open) | 67.65 | 83.21 | 65.80 | 73.53 | 83.77 | 80.57 | 74.81 | 74.18 | 74.52 |
| Qwen3-Omni-30B-A3B-Thinking (Open) | 65.97 | 80.92 | 65.80 | 71.57 | 85.06 | 80.57 | 76.04 | 70.73 | 73.60 |
| Gemini 2.5 Flash (Closed) | 73.82 | 66.41 | 72.04 | 68.03 | 78.67 | 81.87 | 69.86 | 77.09 | 73.06 |
| Qwen3-Omni-30B-A3B-Instruct (Open) | 66.81 | 80.92 | 64.77 | 66.34 | 81.17 | 81.14 | 71.87 | 71.82 | 71.85 |
| Gemini 2.0 Flash (Closed) | 62.18 | 73.28 | 63.73 | 63.72 | 76.62 | 75.43 | 67.23 | 68.55 | 67.84 |
| Qwen2.5-Omni-7B-Instruct (Open) | 48.32 | 69.47 | 58.55 | 58.17 | 76.62 | 73.14 | 64.61 | 59.09 | 62.07 |
| Gemini 2.5 Flash Lite (Closed) | 57.56 | 68.70 | 56.48 | 52.61 | 79.22 | 69.71 | 63.52 | 60.00 | 61.90 |
| Daily-Omni-Baseline-Qwen2.5 (Open) | 51.68 | 68.70 | 60.10 | 53.92 | 78.57 | 71.43 | 63.99 | 59.27 | 61.82 |
| Gemini 2.0 Flash Lite (Closed) | 55.04 | 64.89 | 58.03 | 54.25 | 74.03 | 72.00 | 62.44 | 60.00 | 61.32 |
| Qwen2.5-Omni-3B-Instruct (Open) | 50.84 | 69.47 | 53.89 | 53.92 | 75.97 | 70.29 | 62.60 | 57.45 | 60.23 |
| Ola (7B) (Open) | 40.34 | 61.07 | 40.41 | 43.46 | 63.64 | 69.71 | 51.47 | 49.82 | 50.71 |
| VideoLLaMA2 (7B) (Open) | 35.71 | 35.88 | 35.75 | 31.70 | 40.91 | 34.29 | 38.02 | 31.82 | 35.17 |
| Unified-IO-2 XL (3B) (Open) | 30.25 | 30.53 | 25.39 | 29.08 | 33.12 | 21.71 | 28.13 | 28.55 | 28.32 |
| Unified-IO-2 XXL (8B) (Open) | 25.63 | 31.30 | 26.42 | 25.82 | 35.06 | 29.71 | 26.74 | 30.00 | 28.24 |
| Unified-IO-2 L (1B) (Open) | 27.31 | 22.90 | 26.42 | 27.78 | 29.87 | 29.14 | 27.67 | 27.09 | 27.40 |
† Qwen3.5-Omni-Plus returned valid answers for 1,175 of 1,197 samples. The remaining 22 samples could not be evaluated after repeated API attempts because of request-size limits (13) and content filtering (9). Scores use the valid API responses in each subset as the denominator.
| Methods | AV Align | Comp. | Ctx. Und. | Evt. Seq. | Infer. | Reas. | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct (Open) | 47.90 | 67.18 | 56.48 | 53.92 | 70.78 | 61.14 | 57.96 | 57.64 | 57.81-14.0 |
| Qwen3-Omni-30B-A3B-Thinking (Open) | 44.96 | 64.89 | 55.96 | 59.48 | 67.53 | 60.00 | 56.26 | 59.45 | 57.73-15.9 |
| Gemini 2.0 Flash (Closed) | 39.08 | 64.12 | 56.48 | 56.21 | 67.53 | 62.29 | 56.57 | 55.45 | 56.06-11.8 |
| Gemini 2.0 Flash Lite (Closed) | 43.70 | 58.02 | 53.89 | 45.10 | 64.29 | 60.57 | 53.01 | 51.64 | 52.38-8.9 |
| Qwen2.5-Omni-7B-Instruct (Open) | 34.45 | 58.78 | 47.67 | 49.67 | 62.99 | 54.86 | 48.69 | 51.09 | 49.79-12.3 |
| Qwen2.5-Omni-3B-Instruct (Open) | 37.39 | 51.91 | 44.56 | 41.18 | 64.29 | 48.00 | 46.52 | 45.64 | 46.12-14.1 |
| Gemini 2.5 Flash (Closed) | 37.55 | 37.21 | 40.43 | 44.78 | 57.05 | 53.29 | 42.35 | 47.46 | 44.61-28.5 |
| Gemini 2.5 Flash Lite (Closed) | 36.97 | 45.80 | 37.31 | 39.54 | 59.74 | 47.43 | 44.67 | 41.27 | 43.11-18.8 |
| Methods | AV Align | Comp. | Ctx. Und. | Evt. Seq. | Infer. | Reas. | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct (Open) | 54.20 | 69.47 | 51.81 | 51.63 | 74.03 | 78.86 | 63.37 | 58.18 | 60.99-10.9 |
| Qwen3-Omni-30B-A3B-Thinking (Open) | 54.62 | 67.94 | 49.22 | 51.31 | 77.27 | 77.71 | 65.22 | 55.27 | 60.65-13.0 |
| Gemini 2.5 Flash (Closed) | 46.64 | 55.73 | 44.56 | 42.48 | 70.78 | 78.86 | 55.64 | 52.18 | 54.05-19.0 |
| Gemini 2.5 Flash Lite (Closed) | 42.02 | 61.83 | 41.97 | 45.10 | 68.83 | 65.14 | 54.25 | 48.91 | 51.80-10.1 |
| Methods | AV Align | Comp. | Ctx. Und. | Evt. Seq. | Infer. | Reas. | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-30B-A3B-Instruct (Open) | 47.48 | 68.70 | 52.33 | 55.88 | 67.53 | 61.14 | 57.34 | 57.27 | 57.31 |
| Qwen3-VL-8B-Instruct (Open) | 44.54 | 63.36 | 50.78 | 59.80 | 69.48 | 58.86 | 56.41 | 57.27 | 56.81 |
| GPT-4o (Closed) | 47.90 | 62.60 | 52.33 | 52.61 | 66.23 | 66.29 | 55.64 | 57.45 | 56.47 |
| Qwen3-VL-4B-Instruct (Open) | 43.70 | 61.07 | 54.40 | 53.27 | 68.18 | 58.86 | 54.40 | 56.00 | 55.14 |
| Qwen2.5-VL-7B-Instruct (Open) | 36.97 | 46.56 | 33.68 | 37.91 | 51.95 | 44.00 | 39.26 | 42.36 | 40.68 |
| Qwen2.5-VL-3B-Instruct (Open) | 35.71 | 43.51 | 34.72 | 33.66 | 43.51 | 39.43 | 37.71 | 37.09 | 37.43 |
| Methods | AV Align | Comp. | Ctx. Und. | Evt. Seq. | Infer. | Reas. | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Audio Flamingo 3 (7B) (Open) | 40.76 | 55.73 | 43.01 | 40.52 | 65.58 | 68.00 | 50.23 | 49.45 | 49.87 |
| Qwen2-Audio (7B) (Open) | 28.99 | 35.88 | 27.46 | 32.03 | 33.77 | 33.14 | 31.22 | 31.82 | 31.50 |
| Methods | AV Align | Comp. | Ctx. Und. | Evt. Seq. | Infer. | Reas. | 30s | 60s | Avg |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o (Closed) | 33.19 | 43.51 | 28.50 | 30.39 | 44.81 | 46.86 | 36.48 | 36.18 | 36.34 |
| Deepseek-V3 (671B) (Closed) | 31.93 | 41.22 | 29.02 | 29.41 | 44.81 | 46.29 | 35.24 | 36.00 | 35.59 |
| Qwen2.5-14B-Instruct (Open) | 30.25 | 39.69 | 27.98 | 28.43 | 42.21 | 42.86 | 32.15 | 35.82 | 33.83 |
@misc{zhou2026dailyomniaudiovisualreasoningtemporal,
title={Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities},
author={Ziwei Zhou and Rui Wang and Zuxuan Wu and Yu-Gang Jiang},
year={2026},
eprint={2505.17862},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.17862},
}